旅行者一号探测器在浩瀚的宇宙中享受星际之旅,飞行的几十年来它不仅看过许多景色,而且还用照片的形式记录下来了,人类喜出望外的同时发现旅行者一号发回神秘照片竟然透露着恐怖,这些照片有何恐怖之处呢?下面小编就和大家一起了解下吧!...
发布时间:2024-09-21 06:02:48
:大规模场景下Prometheus的优化手段")
Prometheus 几乎已成为监控领域的事实标准,它自带高效的时序数据库存储,可以让单台 Prometheus 能够高效的处理大量的数据,还有友好并且强大的 PromQL 语法,可以用来灵活的查询各种监控数据以及配置告警规则,同时它的 pull 模型指标采集方式被广泛采纳,非常多的应用都实现了 Prometheus 的 metrics 接口以暴露自身各项数据指标让 Prometheus 去采集,很多没有适配的应用也会有第三方 exporter 帮它去适配 Prometheus,所以监控系统我们通常首选用 Prometheus,本系列文章也将基于 Prometheus 来打造云原生环境下的大型分布式监控系统。
大规模场景下 Prometheus 的痛点概述
Prometheus 本身只支持单机部署,没有自带支持集群部署,也就不支持高可用以及水平扩容,在大规模场景下,最让人关心的问题是它的存储空间也受限于单机磁盘容量,磁盘容量决定了单个 Prometheus 所能存储的数据量,数据量大小又取决于被采集服务的指标数量、服务数量、采集速率以及数据过期时间。在数据量大的情况下,我们可能就需要做很多取舍,比如丢弃不重要的指标、降低采集速率、设置较短的数据过期时间(默认只保留15天的数据,看不到比较久远的监控数据)。
这些痛点实际也是可以通过一些优化手段来改善的,下面我们来细讲一下。
从服务维度拆分 Prometheus
Prometheus 主张根据功能或服务维度进行拆分,即如果要采集的服务比较多,一个 Prometheus 实例就配置成仅采集和存储某一个或某一部分服务的指标,这样根据要采集的服务将 Prometheus 拆分成多个实例分别去采集,也能一定程度上达到水平扩容的目的。
:大规模场景下Prometheus的优化手段")
通常这样的扩容方式已经能满足大部分场景的需求了,毕竟单机 Prometheus 就能采集和处理很多数据了,很少有 Prometheus 撑不住单个服务的场景。不过在超大规模集群下,有些单个服务的体量也很大,就需要进一步拆分了,我们下面来继续讲下如何再拆分。
对超大规模的服务做分片
想象一下,如果集群节点数量达到上千甚至几千的规模,对于一些节点级服务暴露的指标,比如 kubelet 内置的 cAdvisor 暴露的容器相关的指标,又或者部署的 DeamonSet node-exporter 暴露的节点相关的指标,在集群规模大的情况下,它们这种单个服务背后的指标数据体量就非常大;还有一些用户量超大的业务,单个服务的 Pod 副本数就可能过千,这种服务背后的指标数据也非常大,当然这是最罕见的场景,对于绝大多数的人来说这种场景都只敢 YY 一下,实际很少有单个服务就达到这么大规模的业务。
针对上面这些大规模场景,一个 Prometheus 实例可能连这单个服务的采集任务都扛不住。Prometheus 需要向这个服务所有后端实例发请求采集数据,由于后端实例数量规模太大,采集并发量就会很高,一方面对节点的带宽、CPU、磁盘 IO 都有一定的压力,另一方面 Prometheus 使用的磁盘空间有限,采集的数据量过大很容易就将磁盘塞满了,通常要做一些取舍才能将数据量控制在一定范围,但这种取舍也会降低数据完整和精确程度,不推荐这样做。
那么如何优化呢?我们可以给这种大规模类型的服务做一下分片(Sharding),将其拆分成多个 group,让一个 Prometheus 实例仅采集这个服务背后的某一个 group 的数据,这样就可以将这个大体量服务的监控数据拆分到多个 Prometheus 实例上。
:大规模场景下Prometheus的优化手段")
如何将一个服务拆成多个 group 呢?下面介绍两种方案,以对 kubelet cAdvisor 数据做分片为例。
第一,我们可以不用 Kubernetes 的服务发现,自行实现一下 sharding 算法,比如针对节点级的服务,可以将某个节点 shard 到某个 group 里,然后再将其注册到 Prometheus 所支持的服务发现注册中心,推荐 consul,最后在 Prometheus 配置文件加上 consul_sd_config 的配置,指定每个 Prometheus 实例要采集的 group。
在未来,你甚至可以直接利用 Kubernetes 的 EndpointSlice 特性来做服务发现和分片处理,在超大规模服务场景下就可以不需要其它的服务发现和分片机制。不过暂时此特性还不够成熟,没有默认启用,不推荐用(当前 Kubernentes 最新版本为 1.18)。
第二,用 Kubernetes 的 Node 服务发现,再利用 Prometheus relabel 配置的 hashmod 来对 Node 做分片,每个 Prometheus 实例仅抓其中一个分片中的数据:
拆分引入的新问题
前面我们通过不同层面对 Prometheus 进行了拆分部署,一方面使得 Prometheus 能够实现水平扩容,另一方面也加剧了监控数据落盘的分散程度,使用 Grafana 查询监控数据时我们也需要添加许多数据源,而且不同数据源之间的数据还不能聚合查询,监控页面也看不到全局的视图,造成查询混乱的局面。
:大规模场景下Prometheus的优化手段")
要解决这个问题,我们可以从下面的两方面入手,任选其中一种方案。
集中数据存储
我们可以让 Prometheus 不负责存储,仅采集数据并通过 remote write 方式写入远程存储的 adapter,远程存储使用 OpenTSDB 或 InfluxDB 这些支持集群部署的时序数据库,Prometheus 配置:
然后 Grafana 添加我们使用的时序数据库作为数据源来查询监控数据来展示,架构图:
:大规模场景下Prometheus的优化手段")
这种方式相当于更换了存储引擎,由其它支持存储水平扩容的时序数据库来存储庞大的数据量,这样我们就可以将数据集中到一起。OpenTSDB 支持 HBase,BigTable 作为存储后端,InfluxDB 企业版支持集群部署和水平扩容(开源版不支持)。不过这样的话,我们就无法使用友好且强大的 PromQL 来查询监控数据了,必须使用我们存储数据的时序数据库所支持的语法来查询。
Prometheus 联邦
除了上面更换存储引擎的方式,还可以将 Prometheus 进行联邦部署。
:大规模场景下Prometheus的优化手段")
简单来说,就是将多个 Prometheus 实例采集的数据再用另一个 Prometheus 采集汇总到一起,这样也意味着需要消耗更多的资源。通常我们只把需要聚合的数据或者需要在一个地方展示的数据用这种方式采集汇总到一起,比如 Kubernetes 节点数过多,cAdvisor 的数据分散在多个 Prometheus 实例上,我们就可以用这种方式将 cAdvisor 暴露的容器指标汇总起来,以便于在一个地方就能查询到集群中任意一个容器的监控数据或者某个服务背后所有容器的监控数据的聚合汇总以及配置告警;又或者多个服务有关联,比如通常应用只暴露了它应用相关的指标,但它的资源使用情况(比如 CPU 和 内存)由 cAdvisor 来感知和暴露,这两部分指标由不同的 Prometheus 实例所采集,这时我们也可以用这种方式将数据汇总,在一个地方展示和配置告警。
更多说明和配置示例请参考官方文档:https://prometheus.io/docs/prometheus/latest/federation/
Prometheus 高可用
虽然上面我们通过一些列操作将 Prometheus 进行了分布式改造,但并没有解决 Prometheus 本身的高可用问题,即如果其中一个实例挂了,数据的查询和完整性都将受到影响。
我们可以将所有 Prometheus 实例都使用两个相同副本,分别挂载数据盘,它们都采集相同的服务,所以它们的数据是一致的,查询它们之中任意一个都可以,所以可以在它们前面再挂一层负载均衡(比如 Nginx 或 HAProxy),所有查询都先经过这个负载均衡再到其中一台 Prometheus,如果其中一台挂掉就从负载列表里踢掉不再转发。
这里的负载均衡可以根据实际环境选择合适的方案,可以用 Nginx 或 HAProxy,在 Kubernetes 环境,通常使用 Kubernentes 的 Service,由 kube-proxy 生成的 iptables/ipvs 规则转发,如果使用 Istio,还可以用 VirtualService,由 Envoy sidecar 去转发。
:大规模场景下Prometheus的优化手段")
这样就实现了 Prometheus 的高可用,简单起见,上面的图仅展示单个 Prometheus 的高可用,当你可以将其拓展,代入应用到上面其它的优化手段中,实现整体的高可用。
总结
通过本文一系列对 Prometheus 的优化手段,我们在一定程度上解决了单机 Prometheus 在大规模场景下的痛点,但操作和运维复杂度比较高,并且不能够很好的支持数据的长期存储(long term storage)。对于一些时间比较久远的监控数据,我们通常查看的频率很低,但也希望能够低成本的保留足够长的时间,数据如果全部落盘到磁盘成本是很高的,并且容量有限,即便利用水平扩容可以增加存储容量,但同时也增大了资源成本,不可能无限扩容,所以需要设置一个数据过期策略,也就会丢失时间比较久远的监控数据。
对于这种不常用的冷数据,最理想的方式就是存到廉价的对象存储中,等需要查询的时候能够自动加载出来。Thanos 可以帮我们解决这些问题,它完全兼容 Prometheus API,提供统一查询聚合分布式部署的 Prometheus 数据的能力,同时也支持数据长期存储到各种对象存储(无限存储能力)以及降低采样率来加速大时间范围的数据查询。
下一篇我们将会介绍 Thanos 的架构详解,敬请期待。
文章来源:云原生知识宇宙, 点击查看原文 。

旅行者一号探测器在浩瀚的宇宙中享受星际之旅,飞行的几十年来它不仅看过许多景色,而且还用照片的形式记录下来了,人类喜出望外的同时发现旅行者一号发回神秘照片竟然透露着恐怖,这些照片有何恐怖之处呢?下面小编就和大家一起了解下吧!...
发布时间:2024-09-21 06:02:48
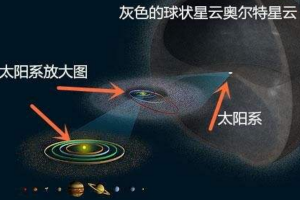
随着科技的光速发展,人类不仅可以遁地还可以上天,甚至是飞跃地球,直奔太阳系而去,例如旅行者1号探测器穿越了太阳圈飞向更远的地方,不过人类始终都无法飞跃奥尔特星云,这到底是为何呢?接下来小编给大家科普一下吧!...
发布时间:2024-09-21 05:00:50
曾经媒体就报道过在11月份的时候会有一个小行星慢慢的接近地球,11月是一个特殊的月份,既有天空中的奇观,还有美国的总统大选即将开始。但是这颗小星星,人们在猜想会在哪个地方与地球亲密的接触。然而,专业人士给出的答案是这颗小星星,不一定会完全的跟地球接触,不会相撞。...
发布时间:2024-09-04 01:02:11

病毒与其他生命一样具有繁殖能力,但是无法独立生存,和其他生命有着很大的差别,那么病毒到底是不是生命呢?下面小编带大家来了解一下吧!...
发布时间:2024-07-21 14:00:15

以叶子为主食的叶猴,相信很多人都听过,前面介绍了黑叶猴,我们今天要认识是灰叶猴,它毛色以灰色为主,生活在中国云南,近些年因为生活环境被破坏,数量也一度剧减,现已成为中国国家一级保护动物,碰到它们我们应该保护!...
发布时间:2024-07-19 00:00:09

人体有很多的器官,其中包括五脏以及六腑。这些器官每个人都有,但是也有个别的人出现畸形的情况,那么就会出现器官的缺失,有些人是先天性的,而有些人是由于后天的环境以及生活而影响。对于五脏六腑来讲,必须要达到完全健康,所以人的状态才会很好。每个人都要对自己的身体负责,所以不论是饮食还是工作都要合理。...
发布时间:2024-07-18 15:00:08

叶猴是指那种主要以叶子为食的猴子,它们有很多种,不过在中国只有6种叶猴,即白头叶猴、长尾叶猴、菲氏叶猴、戴帽叶猴、白臀叶猴和黑叶猴。今天小编重点为大家介绍黑叶猴,它除了手臂短外,长的跟白颊长臂猿相似,接下来一起去认识看看。...
发布时间:2024-07-15 18:00:08

斑林狸是灵猫科、林狸属动物,它与大灵猫长的很相似,是一种毛皮色泽鲜亮,具有极佳观赏性的动物,让人看了就喜欢。不过随着人类的大量捕杀,还有生活环境的被破坏,斑林狸数量剧减,现已是国家二级保护动物,所以就算你遇到了也不要捉回家养,不然就犯法了!...
发布时间:2024-07-15 03:03:46

钱姓排于百家姓中的第二位,虽然起源和来历并不多,但是钱姓人却分布广泛,成为了中国姓氏中的第二大姓。钱姓的主要来源就是彭祖的儿子篯孚,彭祖的真名叫做篯铿,是因为被尧封于大彭而得姓-彭,而他的儿子篯孚因为掌管着钱财,任职钱府上士,所以便为“钱”姓,所以彭钱是一家。...
发布时间:2024-09-20 20:03:27

胡服最早是由春秋战国时的赵武灵王-赵雍引入中原的,因为当时赵国的地形和地理位置都非常不好,常年深受战争威胁,加上赵武灵王继位之后,时局不稳,周边国家都想要攻打赵国,所以赵武灵王便下令让全员都推行胡服,并且学习骑射,相较于宽大的汉服更加便于行动。...
发布时间:2024-09-20 19:05:44

赛艇运动起源于英国的泰晤士河上,当时还是17世纪,英国泰晤士河上的船工在工作之余经常会举办一些赛船,久而久之就形成了一种习俗,在1715年的时候,为了庆祝英王的卫冕,所以第一次正式举办了赛艇比赛,最终在1775年发展为一个正式的运动项目,并且成立了相应的运动俱乐部。...
发布时间:2024-09-20 18:04:28

人们之所以不愿意或者不敢以“宸”为名,主要是因为在古时候“宸”有着“深邃的房屋”的意思,也就是专指皇帝的居住场所,象征着无上的权力,所以“宸”字自然也就成为了禁忌,不过现代人大多是害怕这个字的气势,普通人的命格扛不住。...
发布时间:2024-09-20 17:00:53

商细蕊是电视剧《鬓边不是海棠红》中的京剧名旦,很多人都为他和海归商人程凤台的知己故事而动容,但遗憾的是在历史长河中并没有商细蕊真正的原型,只能说他可能是作者根据历史上著名的京剧名旦构建的一个角色,因为他和梅兰芳、程砚秋、尚小云以及徐碧云等四人的经历和性格都有着极为相似之处。...
发布时间:2024-09-20 16:05:01

在中华上下五千年的历史长河中,除了王朝更替的政治生活与文化生活,还有一些美貌的女子点缀着历史的绘卷,那么在悠悠岁月中有哪些著名的美女呢?下面小编就来为大家盘点一下吧!...
发布时间:2024-09-20 15:04:04

谈及古代帝王,最让人津津乐道的当属那后宫佳丽三千,不过也不是所有的帝王都有那么充实的后宫,比如历史上有一位皇帝就只有一位妻子,是不是让人有点不敢相信,下面小编就带大家一起了解下吧!...
发布时间:2024-09-20 14:01:05

自古无情帝王家,说到帝王的爱情多是奢望,很多帝王后宫的妃子换了一个又一个,几乎都是薄情寡义的,但是漫长的历史长河中也有例外,有的皇帝便与众不同,特别的长情,下面小编来为大家介绍一下历史上最长情的皇帝吧!...
发布时间:2024-09-20 13:03:24

可以说人的成长伴随着无数的武侠剧,尤其是电视剧中的那些绝世高手更是让人影响深刻,有不少人小时候都幻想过可以武功盖世,一统江湖,那么有人知道武侠剧中有哪些绝世高手吗?下面小编为大家盘点一下吧!...
发布时间:2024-09-20 12:02:19

古装电视剧中有许多的美丽的女子,她们身着美丽的衣裳,一举一动摇曳生姿,美得让人挪不开双眼,可以说是一场视觉盛宴,下面就让小编为大家盘点一下那些古装美女吧!...
发布时间:2024-09-20 11:09:01

近年清朝古装剧收视率暴涨,这些电视剧不仅剧情引人入胜,身着清装的美人也同样吸引了不少目光,有着让人过目不忘的美貌,那么清朝古装剧中有哪些美人呢?下面小编就来为大家盘点一下吧!...
发布时间:2024-09-20 11:02:08

养龟市场上经常可以看到小青龟,这种乌龟乖巧可爱以及性情温顺,所以很多人都会选择小青龟来饲养,不过一直都是见到小青龟都比较小,这不禁令人好奇这种乌龟能长多大?下面小编就带大家一起了解一下小青龟吧!...
发布时间:2024-09-20 10:01:47










